
à la suite d'une formation distillée par l'enthousiaste et sympathique Gautier Poupeau (aka @lespetitescases), gentiment proposée et organisée par le ccsd, je vais tenter de résumer, en quelques posts, ce que j'ai retenu d'un sujet auquel je ne connaissais absolument rien! à savoir :
Le Web sémantique
Pour bien commencer il faut se débarasser de fausses idées qui peuvent rendre la compréhension du concept difficile: on parle de sémantique au sens logique du terme et non au sens linguistique. L'objectif n'est pas de faire des recherches en langage naturel, mais plutôt d'organiser l'information pour faciliter la recherche d'"information utile", c'est à dire avoir un moyen de trouver ce qui nous intéresse, et que ce qui nous intéresse!
Pour le moment un humain est capable d'interroger un moteur de
recherche afin de trouver ce qui l'intéresse, en triant les résultats
qui lui sont retournés. Un programme ne pourra pas réaliser cette
opération de manière automatique : il sera bloqué tôt ou tard par
certaines amibiguités. Pour prendre un exemple parlant, imaginons que je
fasse des recherches sur le goupe de heavy metal japonais
X (si si il existe vraiment) ...
Vous voyez tout de suite le nombre de résultats non musicaux que je vais
être obligé de trier (on appelle ça le bruit: ce sont tous les résultats
qui ne m'intéressent pas, mais que le moteur de recherche me renvoie
quand même). Même en affinant ma requête en tapant "X groupe", je ne
lève pas l'ambiguité /-)
Le moteur de recherche répond à la question "quelles sont les pages les
plus populaires du web contenant les mot clés 'X' et 'groupe'", je n'ai
aucun moyen de limiter le résultat de ma recherche aux groupes de
musique ...
C'est à cette problèmatique que le web sémantique s'intéresse.
Le Web sémantique est en fait un ensemble de technologies visant à structurer les données et à les organiser entre elles, afin de faciliter et d'automatiser la navigation et la recherche au sein de ces données.
Pour simplifier, l'idée est d'ajouter du sens aux documents présents sur
le web, afin d'avoir des résultats de recherche précis et pertinents.
Ces données propres (sans bruit) pourraient ensuite alimentées des
traitements automatiques..
Un enjeu majeur actuel est par exemple la mise à disposition des données
publiques. Barack Obama a été moteur sur ce genre d'initiative qui si
elles commencent à voir le jour aux USA avec le projet
OpenGovernment, se font
encore timides en France. L'ouverture des données publiques, entrainent
la création de nouveaux métiers émergents, notamment le data
journalisme.
L'avènement des web services nous a déjà donné un avant goût de ce type
d'application avec les API.
Mais une API:
- est limitée aux fonctions qu'elle met à disposition
- n'est en général valable que sur une petite portion de données (à l'échelle des données présentent sur le web)
Cet aspect du sujet repose sur des standards technologiques à adopter ou à ajouter à ceux déjà en vigueur sur le web, visant à normaliser la manière dont les données sont structurées et décrites. Il ne s'agit pas de remettre en question le web que nous connaissons aujourd'hui, mais plutôt de l'améliorer.
L'autre aspect, est l'interconnexion et l'ouverture de ces données structurées. En effet pour que le Web Sémantique soit intéressant il faut qu'un maximum de données, de types hétérogènes, puissent être interrogeables. L'interconnexion et l'interropérabilité de ces bases de données permet de naviguer d'une base à l'autre, voir d'agréger des données de provenance différente. Par exemple pour connaître les prochains concerts les plus proche du lieu ou je suis dans mon style de musique préféré, une base de données musicale, évènementielle, et de géolocalisation seront nécessaires. Il faut également que ces bases agrègent une information la plus exhaustive possible.
C'est l'enjeu du projet linked data porté par Tim Berners Lee (qui n'est autre que l'inventeur du web est ce besoin de le préciser) qui rassemble plusieurs bases ayant toute une spécialité thèmatique, et possèdant éventuellement une grammaire spécifique pour décrire les données liées à leur spécialité: ces grammaires sont appelées des ontologies
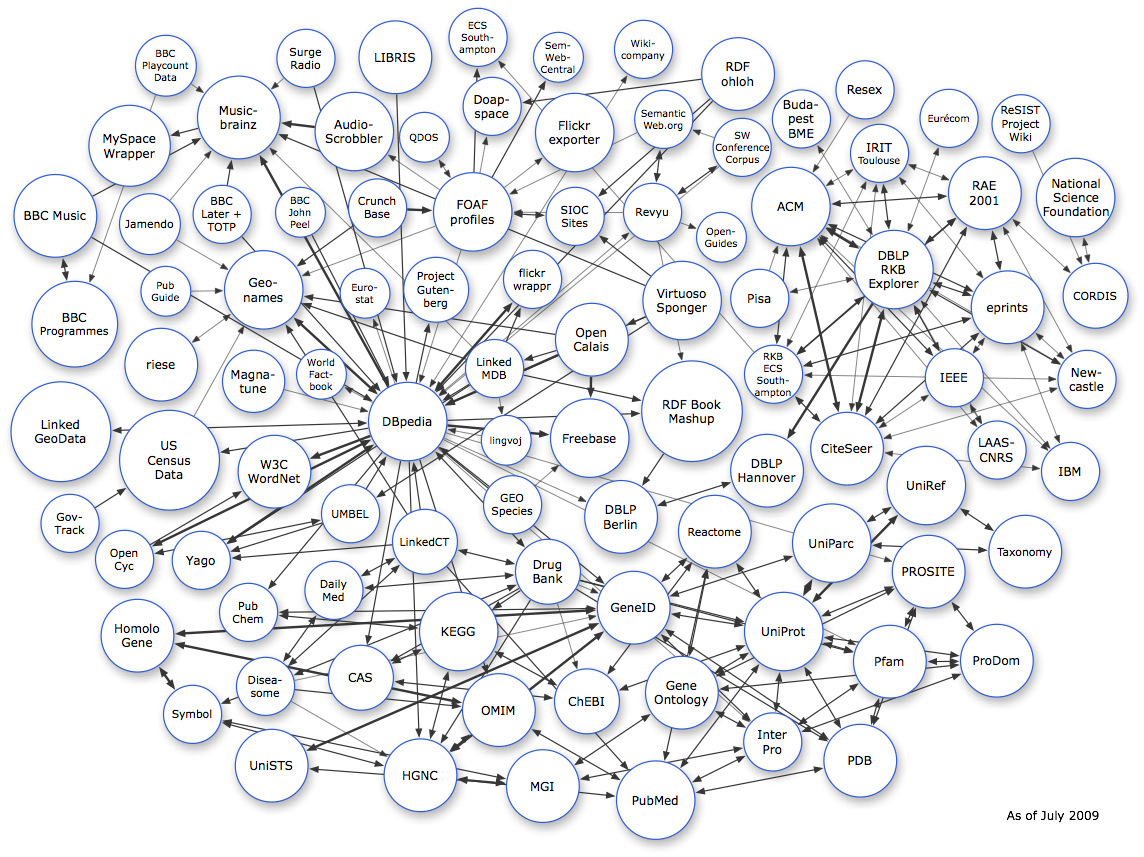
Parmi ces bases l'une des plus vieilles et l'une des plus populaires est sans doute dbpedia. Cette base de connaissance est en fait déduite directement de wikipédia. Plus excatement dbpedia parcourt automatiquement (crawl) wikipédia (en) et structrue de manière sémantique les boites de résumés en haut à droite de toutes les pages qui en ont une. L'information dans ces boites est très structurée et permet à dbpedia de la convertir en triplets RDF. Voyons voir en détails de quoi il s'agit.
Terminologie
L'unité de base est la Ressource.
Tout le formalisme va consister en la définition d'un cadre de
description de ces ressources, d'où le nom de ce formalisme : RDF
(Resource Description
Framework).
Le RDF hérite du XML, et reprend donc en grande partie le paradigme
objet. Ainsi une ressource (qu'on peut voir comme un objet) possède des
propriétés (qu'on peut aussi appeler attributs).
Une ressource est identifiée de manière unique par une URI (Uniform
Resource
Identifier)
qui peut être, si cette ressource est présente sur le web, caractèrisée
par son URL (Uniform Resource
Locator). L'URI
d'une ressource permet d'y faire référence, au sein de la description
d'une autre ressource par exemple.
Une ressource peut avoir plusieurs représentations: Une information au
format RDF, pourra par exemple être affichée en (X)HTML, afin d'être
affichable par un navigateur web.
Une URI répond à un scheme générique
foo://example.com:8042/over/there/index.dtb?type=animal;name=ferret#nose
\ / \_________/ \__/\___________________/ \_____________________/ \__/
| | | | | |
protocole hôte port path requête fragment
Une URI est unique, stable, maitrisable, extensible.
Si je veux parler de symfony par exemple, je me réfèrerais à son uri sur wikipedia http://dbpedia.org/page/Symfony. Si vous voulez parler de moi vous vous réfèrerrez à mon profile FOAF http://vincent.mazenod.fr/oim.rdf#VM.
Le RDF a pour but de typer les ressources, de les décrire, de les lier
entre elles et de qualifier les liens qui les unissent.
L'idée est de séparer la logique des données, de la logique applicative.
Vous allez me "dire il n'y a rien de révolutionnaire dans ce que tu
viens de dire, voilà des années que je design des bases de données, et
que je sépare la logique des données de la logique applicative". Et je
vous répondrez "Oui mais il ne s'agit pas tout à fait de la même
séparation".
Considérons une jointure SQL, qui serait le résultat d'un lien entre
deux tables, découlant d'une analyse UML ou entité association de ce
genre

Une fois implémenté en base de données, on perd 'linformation concernant
la nature du lien unissant ces deux tables. Les contraintes d'intégrité
référentielles (si elles sont bien construites) indiquent qu'un lien
existe entre ces deux tables (clé étrangère), mais sans la logique
applicative on ne peut pas en dire plus.
Le Web semantic tend à déporter le plus de renseignements possibles dans
les données, y compris la description des liens entre données.
L'unité de base de l'intelligence dans les données est le triplet
RDF, c'est
un modèle générique qui permet de décrire toute donnée ou relation entre
donnée en trois parties.
Un triplet RDF se compose :
- Le sujet (encore appelé domaine) représente la ressource à décrire ;
- Le prédicat (encore appelé propriété) représente un type de propriété applicable à cette ressource ;
- L'objet (encore appelé co-domaine) représente une donnée ou une autre ressource : c'est la valeur de la propriété.
un triplet RDF peut se représenter comme un vecteur (sujet, prédicat,
objet) mais aussi comme un graph orienté, en effet le sujet et l'objet
peuvent être vu comme des noeuds, et le prédicat comme l'arête qui
décrit l'association qu'il y a entre le sujet et l'objet. Cette arête
est orientée puisqu'elle n'est valable que dans un sens.
Une association est aussi répérée par une URI. Par exemple si je veux
exprimer que je suis intéressé par
Symfony, en tant que foaf
personne, je ferais référence
au prédicat ayant pour URI http://xmlns.com/foaf/0.1/interest

Notez bien que là c'est bien la foaf:person Vincent Mazenod qui s'intéresse à symfony et que la relation d'intérêt ne fonctionne que dans le sens de la flèche.
Notez également qu'un triplet peut décrire une relation entre deux ressources autant qu'une relation entre une ressource et l'un de ses attributs. Dans ce dernier cas l'attribut de la ressource est lui même vu comme un prédicat, la ressource comme le sujet et l'objet du triplet n'est autre que la valeur de l'attribut. La différence que les formalismes comme UML ou MERISE, font entre liens entre objets et liens entre objets et propriétés, est en WebSémantique complètement effacée.
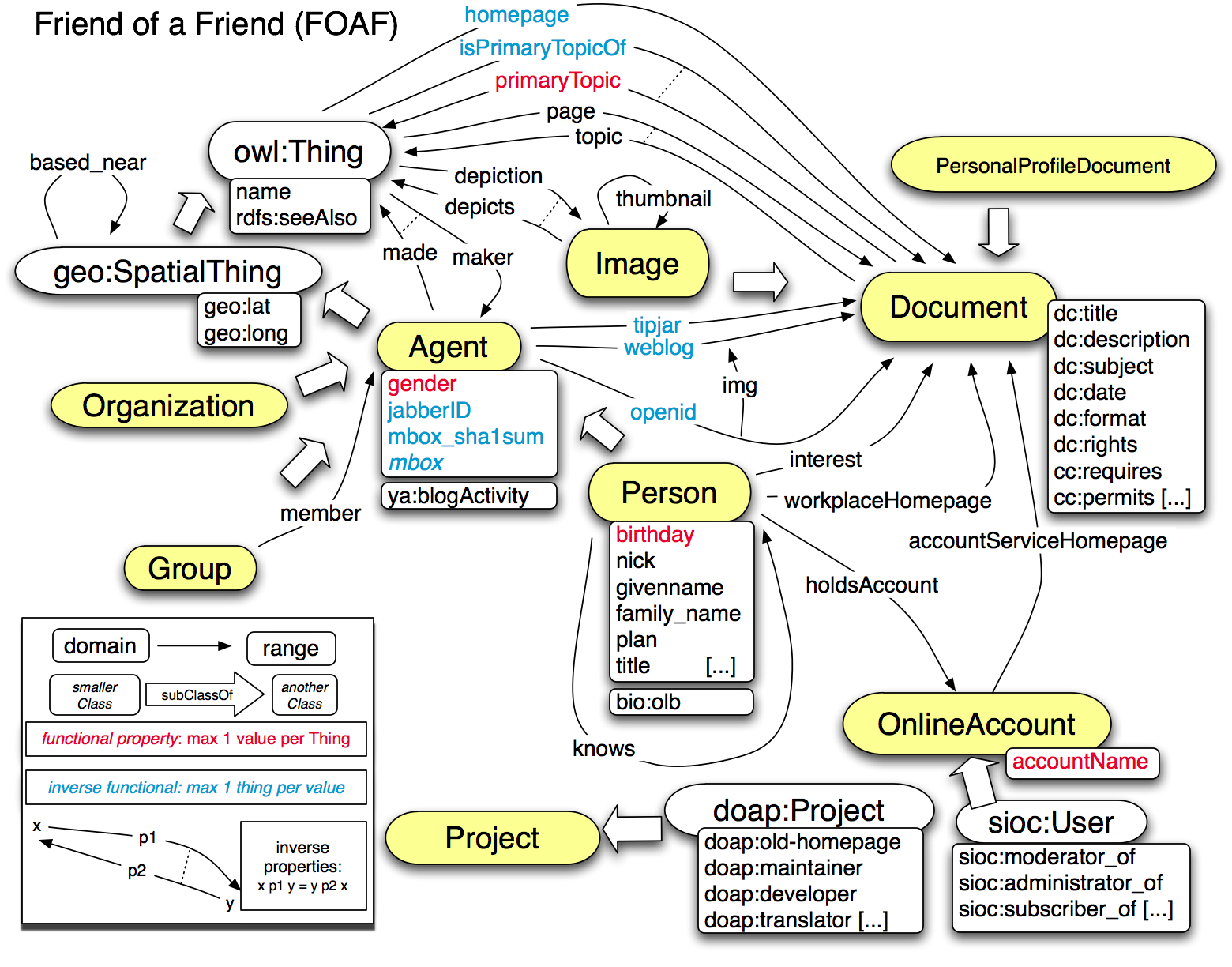
la grammaire permettant de décrire les types de ressources et les liens entre ces ressources, s'appelle une ontologie, il en existe beaucoup , et chacune a sa spécialité, j'ai déjà évoqué l'ontologie FOAF par exemple qui permet de décrire des peronnes et le liens qui les unis. Dbpedia utilise en partie sa propre ontologie. L'ontologie est un système de classification puissant qui permet de lier les concepts entre eux. Elle diffère des sytèmes de classification classiques
{kind=link}
- la folksonomie, ou foutoironomie, ou encore bordelonomie permet à tous de classer des concepts de manière spontanée (i.e. avec les mots que chacun choisit)
- le vocabulaire contrôlé est une folksonomie bornée (i.e. le choix des mots est limité au vocabulaire choisi)
- la taxinomie ou taxonomie permet de hièrarchisés les concepts (i.e. décrire une arborescence)
- le thésaurus est une taxinomie avec possibilité d'une relation transverse entre concept (limitée à la notion d'équivalence ou d'association)
- l'ontologie permet de lier des concepts entre eux et de qualifier finement la relation qui unie chaque concept
Il existe deux languages qui permettent de décrire des ontologies : RDF
Schema &
OWL (owl peut être
vu comme une extension de RDF spécialisé dans la description des
prédicats).
A priori toute ressource hérite au final de owl:Thing. owl:Thing est aux
ontologies qu'il permet de décrire, ce que la classe object est au
langage Java: une classe racine.
En guise de conclusion
Il est assez complexe de présenter le web sémantique de manière ordonné, car beaucoup de concepts sont imbriqués. L'appréhension de ce domaine est d'autant plus compliqué qu'il y a peu d'application directe, testable par l'utilisateur. Dans un propchain post je tenterai de présenter le formalisme RDF plus en détail afin de comprendre les informations supplémentaires et structurées qu'une ontologie permet de décrire. Dans un autre encore je vous parlerai de SPARQL, le langage d'interrogation pour RDF, qui permet d'exécuter des requêtes complexes sur les projets qui composent le web sémantique actuel
Commentaires
comments powered by Disqus