
Une fois qu'on a compris l'intérêt et les concepts de base du web sémantique, on est en droit de se poser la question de la mise en oeuvre effective. Pour ce qui est de mettre à disposition des données structurées il y a déjà les projets impliqués dans linked data qui s'en chargent. Aussi je vous propose de créer une ressource RDF inédite, celle qui vous représente (sémantiquement!) en tant que personne, en utilisant l'ontologie FOAF (Friend Of a Friend).
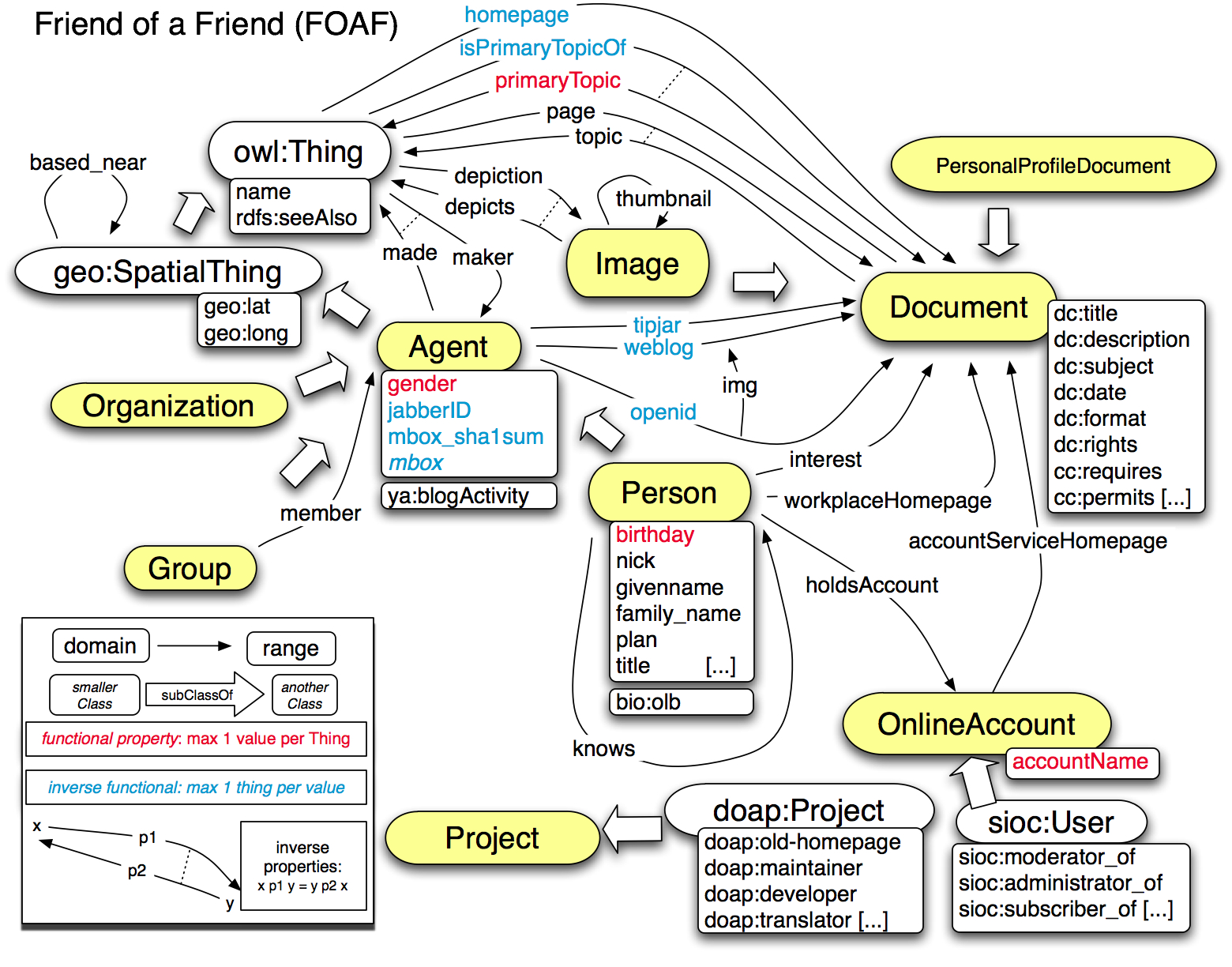
Au vu de ce diagramme de classe, il apparaît qu'une personne est une spécialisation d'un concept plus général : l'agent. L'agent est une chose géolocalisable, qui est une spécialisation de la classe racine owl:Thing l'équivalent de la classe objet java dont je parlais dans mon billet précédent.
Nous utiliserons donc également GEO, une ontologie permettant de décrire des points géolocalisés.
écrire son FOAF profile
Tout d'abord comme je l'avais déjà dit dans ma brève présentation du web sémantique le RDF n'est pas vraiment un language en tant que tel mais plutôt un modèle de descritpion.
Il dérive de XML, aussi la première ligne RDF du fichier n'a rien de surprenant
<?xml version="1.0" encoding="UTF-8"?>
Il s'agit ensuite de définir l'élément racine: le document RDF lui même. Ici chaque ontolige est aliasée par une chaîne de caractères (à la manière d'un name space), ce qui permet d'avoir un code RDF plus clair. Notez que ce n'est pas une obligation et que chaque élément d'une ontologie peut être exprimé par son URI complète, en "nom de balise complet", à tout moment dans le fichier RDF.
<rdf:RDF<br />
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:geo="http://www.w3.org/2003/01/geo/wgs84_pos#">
On décrit ici un élément foaf:Person, et on spécifie l'URI qui lui est associée. Si l'URI n'est pas spécifiée c'est l'URL du document RDF courant qui lui sera attribuée
<foaf:Person rdf:about="http://vincent.mazenod.fr/oim.rdf#VM" foaf:name="Vincent Mazenod">
<foaf:nick>mazenovi</foaf:nick>
</foaf:Person>
Ce triplet a pour sujet foaf:Person, pour prédicat rdf:about, et pour objet http://vincent.mazenod.fr/oim.rdf#VM
il est équivalent au triplet
<rdf:Description rdf:about="http://vincent.mazenod.fr/oim.rdf#VM">
<rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Person" />
<foaf:name>Vincent Mazenod</foaf:name>
<foaf:nick>mazenovi</foaf:nick>
</rdf:Description>
Dans ce dernier exemple, le sujet est exprimé à l'intérieur, de la balise rdf:Description qui spécifie le prédicat et l'objet.
Afin de vous décrire de manière exhaustive vous pouvez chercher dans la liste de propriétés mises à disposiiton par l'ontologie FOAF.
Notez que pour chacune d'elles il est possible de spécifier explicitement le type de données que l'ont fournies à une propriété. Par défaut un type de données est associé à chaque propriété.
<foaf:name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">
Vincent Mazenod
</foaf:name>
Ici le type est forcé en litteral string, qui est le type du contenu de la balise. Evidemment dans ce cas là, forcer le type ne sert à rien puisque ce sont des données de type srting qui sont attendues par la propriété foaf:name.
Pour toute propriété il est également possible de spécifier la langue pour laquelle on donne une valeur
<foaf:gender xml:lang="en">male</foaf:gender>
on pourrait écrire pour traduire la description en français
<foaf:gender xml:lang="fr">homme</foaf:gender>
Le sujet implicite de chacune de ces propriétés est son parent direct, ici l'élément foaf:Person. Le prédicat est la propriété foaf elle même (symbolisée par le nom de la balise), et l'objet est la valeur de la propriété, le contenu de la balise dans le cas d'un chaîne de caractère. En revanche si l'objet est une ressource on y fera référence par son URI dans l'attribut rdf:resoucre. Les centres d'intérêtes notamment s'écrivent comme suit
<foaf:interest rdf:resource="http://dbpedia.org/resource/Bagpipes" />
si l'objet est une ressource il est introduit par l'attribut rdf:resource.

On pourra procéder de cette façon pour faire référence à sa homepage, son blog, sa photo etc ...
Attention toutefois de bien identifier la ressource par son URI et non par son URL, les deux peuvent être différentes. Imaginons que je veuille faire référence à Symfony dans mes centres d'intérêts: si sa page wikipedia est http://en.wikipedia.org/wiki/Symfony, alors son URL sur dbpedia est http://dbpedia.org/page/Symfony, mais cette URL n'est pas la version RDF de la ressource à laquelle je veux faire référence, l'URI de la ressource est http://dbpedia.org/ressource/Symfony. Pour passer facilement de wikipedia à l'URI dpedia il existe un bookmarklet qui fait la transformation d'url automatiquement.
Il arrive parfois que les balises (qu'on peut aussi appeler les noeuds du graphe) n'expriment pas un triplet, elles ne sont alors là que pour structurer les données. On parle de noeud blanc. C'est le rôle de la balise foaf:based_near qui permet de géolocaliser le profil
<foaf:based_near><br />
<geo:Point geo:lat="48.837" geo:long="2.404"/>
</foaf:based_near>
qui pourrait encore s'écrire avec 2 noeuds blanc comme ceci
<foaf:based_near>
<geo:Point>
<geo:lat>48.837</geo:lat>
<geo:long>2.404</geo:long>
</geo:Point>
<foaf:based_near>
Pour me géolocaliser (c'est à dire trouver ma longitude et ma latitude) j'ai utilisé google maps, et j'ai déduit la latitude et la longitude de l'url. J'aurais aussi pu utiliser http://www.geonames.org et récupérer les informations au format RDF à parir des résultats de recherche
RDF et l'XHTML
vous noterez qu'une fois le fichier RDF bien formé et validé, il apparaît comme un fichier xml dans votre navigateur (au moins dans firefox), ce qui n'est pas très sexy. Pour être à la fois semantic et HTML compliant, il y a plusieurs solutions:
La première est de créer une feuille de style xml au format xsl, qui va simplement permettre de définir une série de règle de conversion, pour que le navigateur puisse créé un rendu du document RDF au format HTML. Pour faire référence à ce fichier xsl dans votre fichier rdf il suffit d'ajouter à l'en-tête du fichier rdf
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" encoding="UTF-8" href="./rdf2html.xsl" version="1.0"?>
Le fihcier rdf2html.xsl que j'utilise est une adaptation simplifiée de celui de Gautier Poupeau qui l'a lui même adapté de celui de Pierre Lindenbaum
La deuxième solution consiste à créé une
Version RDFa
L'approche du RDFa est l'approche inverse de celle que je viens de présenter. Elle consiste non pas en la représentation d'un document structuré en RDF, en HTML, mais elle plutot en l'injection de triplets RDF directement au sein du code XHTML. On peut ainsi "donner du sens" au texte que l'on écrit dans une page web.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN"
"http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
<html
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns="http://www.w3.org/1999/xhtml"
xmlns:dc="http://purl.org/dc/terms/">
<head>
</head>
<body>
<div typeof="foaf:person" about="http://vincent.mazenod.fr/oim.rdf#VM">
je m'appelle <span property="foaf:name">Vincent Mazenod</span>
et je suis surnommé <span property="foaf:nick">mazenovi</span>.
</div>
</body>
</html>
Quelques remarques:
- le sujet d'un triplet se rapporte toujours à l'élément rdf parent, si le parent est la racine le sujet c'est l'url du document
- on utilise l'attribut property comme prédicat si l'objet (le contenu de la balise ou le contenu de l'attribut content) est un litteral
- le contenu de l'attribut content est prioritaire sur la valeur entre les balises
- on utilise l'attrbiut rel comme prédicat si l'objet est une ressource. L'attribut href est alors utilisé pour faire référence à la ressource - l'équivalent du rdf:ressource en RDF pure
- la langue est déterminé par défaut sauf contrindication
En guise de conclusion
Tant que le rdf n'est pas exploité par des moteurs grand public, tout ça ne sert pas à grand chose.
Le sujet a l'air bouillant d'actualité puisque Google commence à indexer le RDF! Il propose d'ailleurs déjà les Google Rich Snippet depuis plus d'un an. Il ne faut pas perdre de vue, que bien que les données structurées facilitent grandement le travail d'indexation de Google, elles représentent également un grand danger pour lui, puisque ce qui fait la force de Google actuellement, c'est d'être le meilleur pour rechercher au sein de données peu ou pas structurées (avec du XHTML dans le meilleur des cas). Les fonctionnalités d'un moteur de recherche sémantique sont a priori tout à fait différentes de celles d'un moteur de recherche traditionnel, un domaine qui resterait à conquérir pour le géant accompli de la recherche qu'est Google.
Facebook, l'autre géant, utilise également le RDFa avec une ontologie propre pour son projet open graph, qui permet d'ajouter des données structurées dans les méta données de vos pages web.
A noter que diaspora le projet facebook killer open source et décentralisé utilise FOAF+SSL pour l'authentification si j'ai bien compris ce qui est écrit ici
Pour finir, si vous mettez votre profil FOAF en ligne n'hésitez pas à me linker (http://vincent.mazenod.fr/oim.rdf#VM) et à me le faire savoir afin que je fasse de même :)
Boite à outils
- générateur FOAF
- RDF validator : valide le fait que le flux rdf xml a bien des triplets
- Check RDFa
- RDFa Distiller : extrait les triplet RDF d'un document RDFa
- Bookmarklet de passage automatique de wikipedia à dbpedia
- RDFa Developper : une extension de validation du RDF et un endpoint SPARQL
Commentaires
comments powered by Disqus